シェルスクリプトとawkによるデータ解析
はじめに
テキスト形式の数値データの処理・解析には、awk+シェルスクリプトが最強である。誇張ではない。これまでエクセルやC言語、FORTRANなどしか知らなかった人には、ぜひawk+シェルスクリプトの世界を体験して欲しい。気象データなど、大量のテキスト形式数値データをいじる人には、人生の転換点と言えるほどの衝撃が待っている。
なお、awk+シェルスクリプトの使用環境は、当然ながらUNIXシェルである。Windowsユーザーは、Cygwinで擬似的にUNIXシェル環境を構築してください。
参考になるページ: 「AWKの第一歩」
大規模データの処理
ここでは、実際にフィールドで観測されたデータを解析してみよう。サンプルは、有名な森林生態観測サイトである、岐阜県高山フラックスサイトで測られた日射(光合成有効放射;Photosynthetic Active Radiation; PAR)のデータである。 sample.txt←このリンクを右クリックなどで保存し(ファイル名はsample.txt)、中を覗いてみよう:
$ cat sample.txt
2005,170,600,1.058,.044,-.033 2005,170,605,.991,.06,.067 2005,170,610,1.022,.033,.087 2005,170,615,1.062,.02,-.017 2005,170,620,1.313,.044,.013 2005,170,625,1.186,.03,-.023 ......
各行に、各年,日付,時刻,センサ1,センサ2,センサ3の順にデータが入っている。日付は、1月1日を1とし、12月31日を365とする、年間通算の日付け(Day of Year またはJulian Dayともいう)、時刻は、1または2桁で時、2桁で分をあらわす(たとえば605は午前6時05分)。各列はコンマで区切られている。
センサは1から3まであり、センサ1は森の樹冠の上に突き出たタワーの上で、空からやってくる光を観測している。センサ2, 3は、林床に設置されており、森の樹冠を透過した光を、それぞれ別の場所で観測している。センサ1〜センサ3の出力は、それぞれセンサの電圧(mV)であらわされており、これを実際の物理的な値(この場合はμmol/m2/sec)に変換するには、それぞれのセンサに固有の係数をかけてやる必要がある。
まず、センサの出力を物理値に変換しよう。別途の較正作業の結果から、センサ1〜センサ3の変換係数は、以下のようにわかっている:
センサ1 センサ2 センサ3 293.73 306.82 290.84
これらの値を、各センサの出力(mV)にかけてやれば、センサの電圧出力は物理値に変換される。それにはawkをこのように使う:
$ cat sample.txt | awk 'BEGIN{FS=","}{print $1,$2,$3, $4*293.73, $5*306.82, $6*290.84}'
2005 170 600 310.766 13.5001 -9.59772 2005 170 605 291.086 18.4092 19.4863 2005 170 610 300.192 10.1251 25.3031 2005 170 615 311.941 6.1364 -4.94428 2005 170 620 385.667 13.5001 3.78092 ......
ここで、BEGIN{FS=","}というのは、「最初にまず、列のさかいめ(field separator,略してFS)はコンマで表す」という意味。これを宣言することで、各行の列をコンマで区切ることが指示される(ちなみにデフォルトではFSはスペースかタブである)。その次の{}内の意味は自明だろう。
次に、時刻を"605"のような時分表示はなく、1日の通算の分で表示しよう。というのも、時分表示では、繰り上がりにギャップが出来るからである(例えば659の次が660でなくて700になる):
$ cat sample.txt | awk 'BEGIN{FS=","}{min=$3%100; hour=($3-min)/100; print $1,$2,min+hour*60, $4*293.73, $5*306.82, $6*290.84}'
2005 170 360 310.766 13.5001 -9.59772 2005 170 365 291.086 18.4092 19.4863 2005 170 370 300.192 10.1251 25.3031 2005 170 375 311.941 6.1364 -4.94428 2005 170 380 385.667 13.5001 3.78092
さらに、時刻を1日単位で日付けにあわせてしまおう。これは、複数の日にまたがるデータを統一的に扱うためである:
$ cat sample.txt | awk 'BEGIN{FS=","}{min=$3%100; hour=($3-min)/100; print $1,$2+(min+hour*60)/1440, $4*293.73, $5*306.82, $6*290.84}'
2005 170.25 310.766 13.5001 -9.59772 2005 170.253 291.086 18.4092 19.4863 2005 170.257 300.192 10.1251 25.3031 2005 170.26 311.941 6.1364 -4.94428 2005 170.264 385.667 13.5001 3.78092
この出力を、"conv.txt"という新規ファイルに入れよう(リダイレクト):
$ cat sample.txt | awk 'BEGIN{FS=","}{min=$3%100; hour=($3-min)/100; print $1,$2+(min+hour*60)/1440, $4*293.73, $5*306.82, $6*290.84}' > conv.txt
このconv.txtをもとに、gnuplotという、コマンドライン対応型のグラフソフト(言いかえれば、グラフを描くためのスクリプト言語)で、センサ1,2,3の観測値の変動のグラフを描こう
(Ubuntu 14.04 では グラフが描画できないことがあるので、その場合は gnuplot-x11 をインストールすること。
$ sudo apt-get install gnuplot-x11 )
$ gnuplot
gnuplot> plot "conv.txt" u 2:3 w l, "conv.txt" u 2:4 w l, "conv.txt" u 2:5 w l
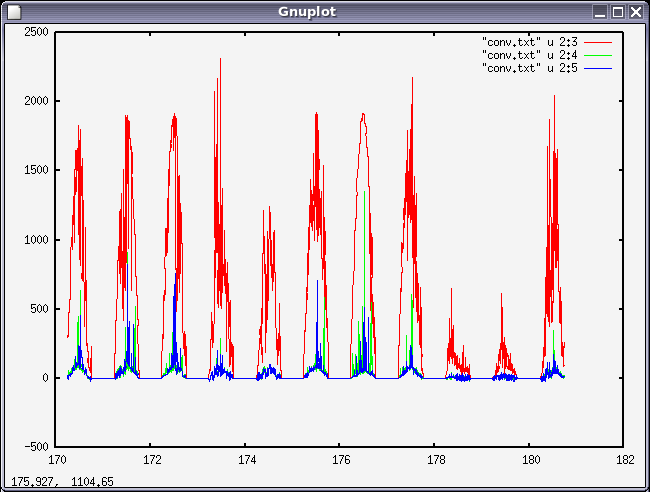
gnuplotから抜けるには、
gnuplot> exit
さて、この一連の処理は、viなどのエディタを使って、以下のようなreadme.shというファイル名のシェルスクリプトにまとめてしまうことができる:
#!/bin/sh
cat sample.txt | \
awk 'BEGIN{FS=","}
{min=$3%60; hour=($3-min)/100; print $1,$2+(min+hour*60)/1440, $4*293.73, $5*306.82, $6*290.84}' > conv.txt
gnuplot <<EOF
set terminal png
set output "Takayama_PAR.png"
set title "Takayama PAR"
set yrange [0:2500]
set ylabel "PAR [umol/m2/sec]"
set xlabel "DOY (2005)"
plot "conv.txt" u 2:3 title "above canopy" w l, "conv.txt" u 2:4 title "under canopy" w l, "conv.txt" u 2:5 title "under canopy" w l
EOF
これをviなどのエディタで作ってreadme.shという名前で保存して、
$ chmod +x readme.sh
$ ./readme.sh
とすれば、一連の処理がぜんぶ自動的に実行され、以下のようなグラフがTakayama_PAR.pngというファイル名でできあがる:
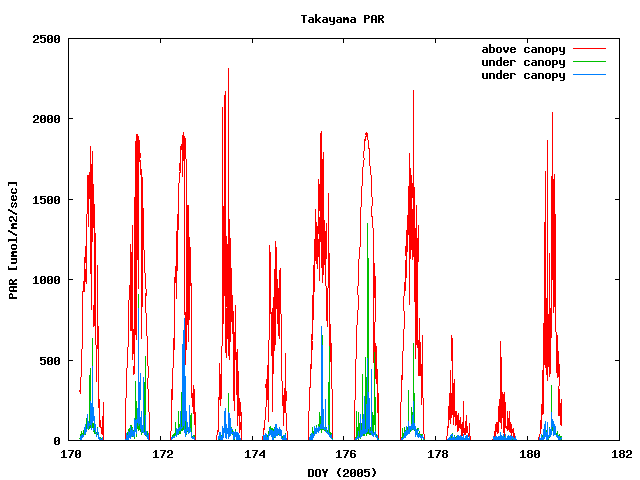
このように処理をシェルスクリプトにすることは、以下のようなメリットがある:
- 1次データから最終結果(グラフ)までの処理工程を全て完全に記録でき、必要ならば簡単に再現できる。
- 同様のデータについて、同様の処理をするときに使いまわすことができる。
- 処理の一部を変更して全てをやり直すのも容易である。たとえばこの例では、センサの出力を物理値に変換する係数を変更する、などの場合である。
- 処理のノウハウを公開したり、他の研究者と共有することが容易である。
ここで述べた1の事項、つまり1次データから最終結果(グラフ)までの処理工程を全て完全に記録するということは、一般にはあまり意識されていないが、実は科学研究では極めて重要なことである。科学者・技術者の倫理として、なんらかの研究・解析をやった結果のデータを世間に発表する前に、その正しさを十分にチェックしなければならないし、発表したあとも、常にそのデータ処理の細部に関して、だれかから問い合わせがあったときに対応できなくてはならない。そのためには、最終的に発表するデータが、どのようなデータから、どのような工程を経て加工されたか、たどれなければならない。これを、「データのトレーサビリティ」と呼ぼう。データのトレーサビリティを確保するためには、データに施した全ての処理を記録する必要がある。シェルスクリプトはそれを実現するのだ。そのようなことを、シェルスクリプトを使わずに、たとえば表計算ソフトなどのグラフィカルインターフェースに基づく処理で行うのは大変である。
統計量の計算
上の例で、こんどはセンサー1の出力について、各日の日積算値を求めてみよう:
$ cat conv.txt | awk 'BEGIN{D=170;a=0;t=170.0}D+1<=$2{print D, a; a=0; D++}{a=a+$3*($2-t)*60*60*24/1000000; t=$2}'
170 46.912 171 44.421 172 47.185 173 27.6938 174 23.9657 175 43.4051 176 55.7856 177 38.7133 178 4.91674 179 4.5035
単位は、mol/dayである。この考え方を使えば、時間ごとの積算や平均値も簡単に計算できる。
もっと簡単な例として、日射(PAR)の、森林樹冠透過率を求めてみよう。センサ2やセンサ3の出力を、センサ1の出力で割れば良い:
$ cat conv.txt | awk '{print $1,$2,$4/$3,$5/$3}'
2005 170.25 0.0434414 -0.0308841 2005 170.253 0.0632432 0.0669434 2005 170.257 0.0337287 0.0842897 2005 170.26 0.0196717 -0.01585 ............... 2005 170.735 -0.0335411 -0.317942 2005 170.753 0 0 2005 170.757 0 0 awk: コマンドライン:1: (FILENAME=- FNR=147) 致命的: ゼロでの除算を行いました。
上のようなエラーが出てしまった。これは、センサ1の出力がゼロのとき、ゼロが分母になるような割り算をすることになってしまうからである。これを回避するには、以下のようにすればよい:
$ cat conv.txt | awk '$3>0{print $1,$2,$4/$3,$5/$3}'
2005 170.25 0.0434414 -0.0308841 2005 170.253 0.0632432 0.0669434 2005 170.257 0.0337287 0.0842897 2005 170.26 0.0196717 -0.01585 ................ 2005 180.725 0.113284 0.0655461 2005 180.728 0.0378628 0.0844489 2005 180.732 0 0.106089 2005 180.735 0.175067 0.0912721
これを、前と同様のグラフにまで描くスクリプトにすると、以下のようになる:
#!/bin/sh
cat conv.txt | awk '$3>0{print $1,$2,$4/$3,$5/$3}' > trans.txt
gnuplot << EOF
set terminal png
set output "Takayama_PAR_trans.png"
set title "Takayama PAR transmittance"
set yrange [0:1]
set ylabel "PAR transmittance"
set xlabel "DOY (2005)"
plot "trans.txt" u 2:3 title "sensor 2" w l, "trans.txt" u 2:4 title "sensor 3" w l
EOF
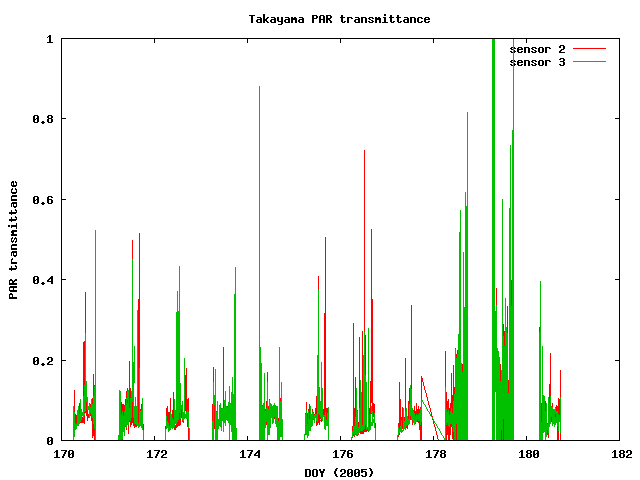
ファイルを並べてくっつけるには?
たとえば、
001 2 002 3 003 1 004 5 005 6
というデータを含む、data1.txtというファイルと、
1 5 4 4 5
というデータを含む、data2.txtというファイルのデータを、横に並べて
001 2 1 002 3 5 003 1 4 004 5 4 005 6 5
というふうなファイルにしたい、ということがよくある。そういうときには、
$ paste data1.txt data2.txt
とすればよい。標準出力に書き出されるから、ファイルにリダイレクトしてもいいし、 パイプでawkなどに流し込んでもよい。3つ以上のファイルのデータをいっぺんに 並べることもできる:
$ paste data1.txt data2.txt data3.txt
Keyword(s):
References:[テキスト処理] [Unix/Linux入門]